
Tumors were first described by the Greek physician Hippocrates (460-377 BC), who classified them into two categories: carcinomas that form ulcer and those that do not. With the invention of the microscope at the end of the nineteenth century, it was then discovered that various types of tumors exist, depending on the type of cells involved. Recently, technology transformed its classification again. In fact, thanks to DNA sequencing, it is possible to distinguish tumors according to the mutations that underlie them. But let’s move one step at the time.
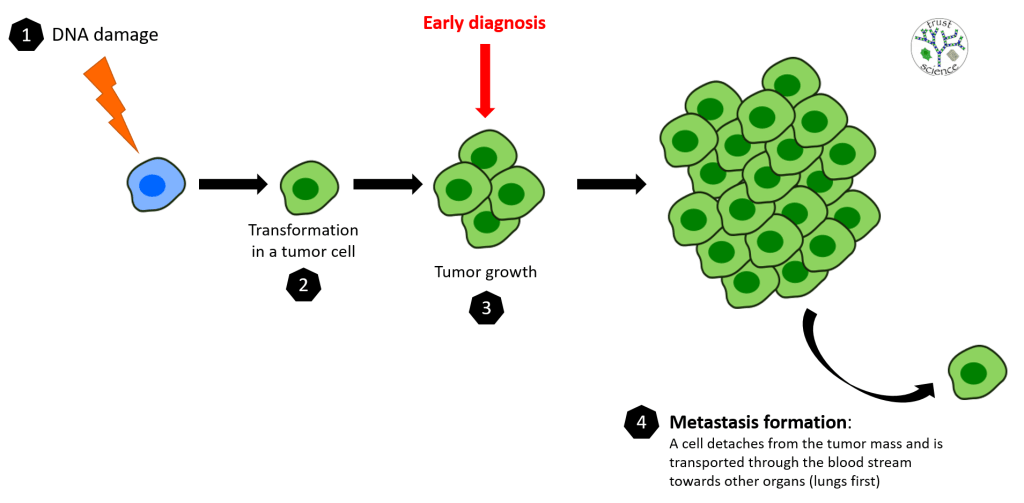
Tumors are caused by DNA damage
DNA can be intended as a long text (approximately 6.4 billion characters) that contains all the information necessary for the development and functioning of our organism. Changing a word may not have any effect (and therefore not cause tangible consequences), but in some cases it may alter its meaning. How do these changes occur (“mutations”, to use the scientific term)? A characteristic example is represented by the sun’s UV rays: due to their frequency, they can damage the DNA contained in the skin cells. Other carcinogens are cigarette smoke, asbestos, alcohol, some food-related factors (nitrite and polyaromatic hydrocarbons generated by barbecued food), but also some bacteria and viruses (the bacterium Helicobacter pylori, papillomavirus and hepatitis viruses). Genetic predisposition is also a risk factor: if a “potentially dangerous” synonym (inherited from one of the parents) were present in a person’s DNA instead of the corresponding “traditional” word, he/she would have a greater risk of developing a tumor.
What happens when a cell’s DNA suffers damage that cannot be repaired? The primary objective is to protect the organism, therefore if a mutation prevents the correct functioning of the cell, preventive mechanisms would be activated to induce it to commit suicide. However, the most dangerous mutations are those that affect these mechanisms, blocking them. In this case, the damaged cell would stop responding to the body’s physiological signals and, instead of eliminating itself, would begin to behave in an uncontrolled way. That’s how a tumor arises. A damaged cell begins to replicate relentlessly (for this reason tumors continue to grow in size), generating millions of identical clones with the same mutation, which makes them a foreign body in the organism.
We learned that tumors are caused by DNA damage. A logical consequence is that the tumor will have different characteristics depending on the the effect of the damage: an alteration in one of the DNA repair mechanisms will have different effects compared to a mutation that involves the control of cell proliferation. Now we better understand the meaning of the first paragraph. DNA sequencing has led to a new way of classifying tumors. “DNA sequencing” means knowing how to read the DNA text. While we are still far from a complete understanding of it, we can recognize the presence of various “errors” that underlie tumorigenesis (the process of tumor formation). Regardless of whether the tumor is located in one organ rather than another, the most effective treatments are those that target the deregulated mechanism, rather than the cell type. To be clear, a pancreatic and a brain tumor could be treated with the same drug, if the mutation that caused them was the same. This is because the ideal drug has the task of reversing, or halting, the biological consequence caused by the mutation. The distinction into categories based on organ and cell type still remains essential, but the current classification of tumors on the basis of genetic origin (therefore on the mutation) is improving the therapeutic choices.
DNA sequencing from various types of cancer allows to identify new mutations that underlie them, and therefore new possible therapeutic targets. For example, two types of lung cancer were known ten years ago: small cell or non-small cell; now more than 30 genetic variants are known. This process has led us to understand that each tumor is rare and the gradual classification into detailed sub-categories brings benefits both in the diagnostic and therapeutic fields. The possibility of screening for different mutations makes the diagnosis specific and accurate; the therapeutic choice adapts accordingly, since some subcategories of a particular tumor are more or less responsive to a given treatment. With a more specific diagnosis compared to a generic “tumor of (organ)”, there is the advantage of knowing in advance which treatments are more likely to be successful and which are to be avoided because they are ineffective for the given tumor subtype.
Tumor diagnosis
In the previous paragraph I introduced the importance of a correct and precise diagnosis of tumors. Another crucial aspect is the time of the diagnosis: the sooner a tumor is diagnosed, the more likely it is that therapies are successful. Instead, if cancer isn’t discovered early enough and spreads from the organ of origin through the body, it becomes unstoppable even for the most sophisticated therapies. Because of this, many investments have been made to improve cancer diagnostics. The sensitivity to detect the presence of cancer cells is constantly increasing (tumors can now be discovered even during the early stages of tumorigenesis, when the malignant mass is still small). To demonstrate the importance of early diagnosis, I bring you some numbers: 89% of patients diagnosed with any type of localized tumor survive at least another 5 years after diagnosis, while the percentage drops to 21% in patients with metastasis (when the tumor has spread to other organs).
Liquid biopsies are revolutionizing the early detection of cancer by allowing doctors to monitor blood instead of taking a tissue sample (with a traditional biopsy). This is because all cells have access to the bloodstream (directly or indirectly) and every potential tumor releases “markers” into the blood that indicate its presence; if you are able to recognize them, you can develop less invasive and highly accurate tests, which can be used in the clinical routine. Later in the article I will present a concrete example about it. Artificial intelligence also begins to play a very important role in diagnostics: computers are “trained” to recognize different tumor subtypes that are indistinguishable to the human eye. This can bring great benefits to the diagnosis, for example, of pancreatic cancer, which is almost always discovered too late and in fact has a very high mortality rate.
Overscreening is dangerous
To avoid late diagnosis, healthcare systems of various countries offer a screening service for people at risk. Breast, prostate, cervix, colorectal and lung cancers are monitored. The low prevalence of the other typologies does not justify their inclusion. A debated issue concerns overscreening for breast and prostate cancer, more aggressive than the others, which instead grow more slowly and homogeneously and therefore do not need to be tested frequently. Overscreening is to run diagnostic tests too frequently and on a large scale. To avoid exaggerated costs, discomfort to people and the risk of clogging hospital facilities, it is necessary to establish a reasonable period of time between one screening and another, without however endangering people’s health. Another important aspect is represented by false positives, that is an incorrect diagnosis of cancer. The case of prostate cancer screening is emblematic: a study reported that up to 75% of positive tests are false positives. These results and the unnecessary biopsies and diagnostic treatments that would follow have negative consequences for people, such as psychological distress, incontinence and erectile dysfunction. In addition, 97% of men whose prostate cancer is kept under control (limiting its growth) rather than treated were still alive 10 years after diagnosis. However, over 90% of pancreatic cancers are treated with radiation or surgery and up to a fifth of people develop heavy sexual, urinary or gastrointestinal side effects. Finally, it must be remembered that not all diagnosed cancers are equivalent to a saved life. Screening can indeed reveal the presence of very low-risk tumors that may never become clinically significant. These diagnoses cause unnecessary fears and anxieties and, as already written, can lead to treatments that would never have been necessary.
How to solve the overscreening issue? One possibility is to deepen our genetic knowledge, in order to identify (with a DNA test) people who are predisposed to a type of potentially malignant tumor, who would then be monitored more carefully. Alternatively, it is necessary to include biomarkers in the diagnostic test that can provide more information on the degree of risk of the tumor detected, in order to know its danger at the time of diagnosis.
The future of tumor screening
Now I describe a very recent approach (developed by GRAIL) that uses a simple blood test to screen over 50 different types of cancer simultaneously. This test has a low frequency of false positives and will be proposed to people at risk (>50 years old), giving priority to potentially lethal tumors if left untreated (to avoid unnecessary psychological stress). A positive result for a tumor will then be followed by more accurate clinical analyzes. One of the discoveries that led to the development of this type of test is that all cells, including cancer cells, release DNA fragments (called cell-free DNA, cfDNA) into the blood. We know that DNA of cancer cells has mutations, which are also present in the cfDNA. If these mutations are known, they can be detected among the various cfDNA fragments in a normal blood sample (the “markers” I referred to earlier). Simple, isn’t it? Too bad there are some heavy limitations: first, tumor cfDNA is extremely rare when compared to the cfDNA of all other cells; second, the mutations in the tumor DNA are few, therefore the possibility that they are present in the small fragments of cfDNA is very low; third, there is a heavy interference by the cfDNA from blood cells, which as they age, they develop mutations similar to the tumor ones (but without becoming tumors), and this might affect the result; fourth, DNA sequencing is not always perfect and potential mistakes could alter the result. So what? Fortunately, biology came to rescue. It is known that DNA can be modified through a process called methylation. Avoiding details, it is enough to know that DNA methylation is equivalent to changing the character of the DNA text: several sentences among the thousands are in italics. In this way, they keep the meaning unchanged, while becoming distinguishable from the rest of the text. DNA methylation is characteristic of the type of cell (the methylation profile of a neuron is different from a lymphocyte’s one) and our luck is that the methylation profile of the tumor DNA is completely different from that of the corresponding healthy cells. Since we have a technology capable of recognizing methylation, GRAIL has used it to distinguish tumor from physiological cfDNA. Earlier I also mentioned artificial intelligence as a support in diagnosis, and GRAIL makes excellent use of it. In fact, they developed a computational model to distinguish the abnormal methylation typical of tumors from the physiological one. This “classifier” has been trained and validated using a database of DNA methylation models of thousands of individuals diagnosed with different types of cancer, so that they can then be then recognized in the patients tested.
A simultaneous early diagnosis test for different types of cancer performed through a blood analysis could reduce the huge burden on patients, their families, health systems and society. It would also make it possible to diagnose rarer, but potentially life-threatening tumors, which are now excluded (for practical and economic reasons) from traditional screening tests.
Sources
https://www.nature.com/articles/d41586-020-00845-4
https://www.nature.com/articles/d41586-020-00840-9
https://www.nature.com/articles/d41586-020-00841-8
https://www.nature.com/articles/d42473-020-00079-y
https://www.sciencedirect.com/science/article/pii/S0923753420360580
